-
[Python 3] BOJ - 13711 "LCS 4"BOJ 2021. 12. 8. 20:41
# 문제 링크
https://www.acmicpc.net/problem/13711
13711번: LCS 4
LCS(Longest Common Subsequence, 최장 공통 부분 수열)문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다. 예를 들어, [1, 2, 3]과 [1, 3, 2]의 LCS는 [1, 2] 또는 [1, 3]
www.acmicpc.net
# 풀이
개인적으로 이 문제의 핵심은 가장 긴 증가하는 수열(LIS)라고 생각한다.

<그림 1. 문제 도식화> 위 그림 1은 입력으로 주어지는 배열 A와 B, 그 때의 정답배열인 C 그리고 각각의 C배열의 원소들이 A와 B에서의 인덱스를 기호화한 그림이다. 문제의 조건에 따라, 정답배열인 C는 반드시 1부터 N까지의 수 중 하나이어야 한다. 또한 $A_{c_1} < A_{c_2} < A_{c_3} < ... < A_{c_k}$를 만족해야 한다. 같은 논리로 $B_{c_1} < B_{c_2} < B_{c_3} < ... < B_{c_k}$ 또한 만족해야 한다. 따라서, 정답 배열은 "인덱스"의 관점으로 본다면 증가하는 수열임을 알 수 있다.
"값"의 관점에서는 C의 각각의 원소에 대해 유일하다는 것은 자명하다. 결국, 달라지는 것은 A에서의 인덱스와 B에서의 인덱스이다.

<그림 2. 정답배열을 고르는 과정 중 일부> 위 그림 2는 임의의 배열이 있을 때 정답 배열 C를 도출하는 과정 중 일부를 나타내는 그림이다. 이 때 화살표는 같은 값끼리 묶어 놓은 것이며, 설명의 편의를 위해 화살표로 나타내었으나 무방향으로 나타내도 상관없다. A를 기준으로 할 때, 현재 정답 배열에 2를 추가한다고 해보자. 현재 정답 배열에는 아무것도 들어있지 않기 때문에 2를 넣어도 상관 없기 때문에 2를 넣는다고 하자.
이후 정답 배열에 1을 추가한다고 해보자. 과연 가능할까? 가능치 않다. 왜냐하면 위 그림 1에서의 논리가 성립하지 않기 때문이다. 즉, $A_{c_1} < A_{c_2}$이지만 $B_{c_1} > B_{c_2}$인 모습이기 때문이다. 이렇게 한쪽 배열만을 기준으로도 정답을 구할 수 있는 이유는 기준이 되는 배열은 무조건 인덱스 기준 오름차순이기 때문에(왼쪽에서 오른쪽으로 순회하기 때문에), 다른 한쪽의 배열의 인덱스값이 LIS를 만족하는지만 확인하면 두 배열 모두 LIS를 만족하는 정답 배열이기 때문이다.
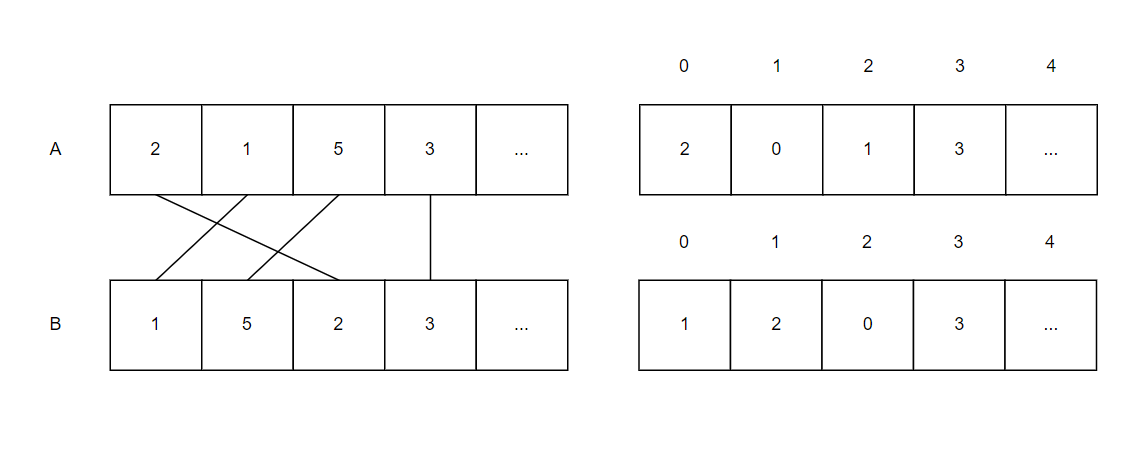
<그림 3. 각 배열을 기준으로 하는 인덱스 배열> 위 그림 3은 각 배열을 기준으로 하는 인덱스 배열을 나타낸 그림이다. 해석하자면, 오른쪽 위 배열을 기준으로, 0번째 값은 2인데, 이는 A[0]의 값인 2가 B에서 2번째 인덱스에 위치한다는 의미이다. 마찬가지로 오른쪽 아래 배열을 해석하면 B[0]인 1이 A에서 1번째 인덱스에 위치한다는 의미이다. 따라서 오른쪽 위쪽 배열은 $A_i$의 B에서의 인덱스를 나타낸 것이고 오른쪽 아래쪽 배열은 반대로 $B_i$의 A에서의 인덱스를 나타낸 것이다. 따라서, 현재 인덱스 배열(오른쪽 배열 그림 중 아무거나 하나)을 기준으로 LIS를 구하고 길이를 출력하면 정답을 구할 수 있다. LIS에 대한 자세한 설명은 여기에서 확인할 수 있다.
# 코드
import sys, bisect # 입력부 n = int(sys.stdin.readline()) a = list(map(int, sys.stdin.readline().split())) b = list(map(int, sys.stdin.readline().split())) # da : 현재 a의 원소의 값을 key, 그 때의 인덱스를 value로 갖는 딕셔너리 da = dict().fromkeys([i for i in range(n + 1)], -1) # da : 현재 b의 원소의 값을 key, 그 때의 인덱스를 value로 갖는 딕셔너리 db = dict().fromkeys([i for i in range(n + 1)], -1) for i in range(n): da[a[i]] = i db[b[i]] = i # arr : A를 기준으로 하는 B배열의 인덱스 배열. 그림 3의 오른쪽 위 배열 그림과 같다 arr = [] for i in range(n): arr.append(db[a[i]]) # lis를 구한다 - O(NlogN) lis = [] for i in range(n): if not lis: lis.append(arr[i]) else: if arr[i] > lis[-1]: lis.append(arr[i]) else: # idx : lower_bound의 인덱스 idx = bisect.bisect_left(lis, arr[i]) lis[idx] = arr[i] # 정답 출력 print(len(lis))'BOJ' 카테고리의 다른 글
[Python 3] BOJ - 2132 "나무 위의 벌레" (0) 2021.12.16 [Python 3] BOJ - 2305 "자리 배치" (0) 2021.12.14 [Python 3] BOJ - 13308 "주유소" (0) 2021.12.04 [Python 3] BOJ - 17182 "우주 탐사선" (0) 2021.11.30 [Python 3] BOJ - 3430 "용이 산다" (0) 2021.11.29