-
Atcoder Beginner Contest 287 후기AtCoder 2023. 2. 5. 18:23
A. Majority
홀수인 n이 주어지고, n개의 숫자가 주어질 때 과반이 동의하는지를 묻는 문제이다
import sys, math n = int(sys.stdin.readline()) d = {"F" : 1, "A" : 0} val = 0 for _ in range(n): temp = sys.stdin.readline().rstrip() val += d[temp[0]] print('Yes' if val >= math.ceil(n / 2) else 'No')B. Postal Card
n개의 문자열과 m개의 문자열이 주어질 때, m개의 문자열 중 하나라도 suffix가 되는 문자열의 갯수를 n개의 문자열에서 찾는 문제이다.

<그림 1. n = 4, m = 3인 경우> 위 그림 1에서 n개의 문자열은 arr라는 배열에, m개의 문자열은 temp라는 배열에 추가하였다. 따라서, arr에서는 345로 끝나는 문자열 하나와 214로 끝나는 문자열 하나가 있으므로 이 때 정답은 2가 된다. n과 m이 각각 1000이 최대값이며 문자열의 길이도 최대 6글자이기 때문에 단순히 구현만 해주면 되나, arr나 temp에 들어오는 문자열 중 중복이 있을 수 있는 점을 유의해야 한다
import sys, math n, m = map(int, sys.stdin.readline().split()) c = [] ans = set() for _ in range(n): c.append(sys.stdin.readline().rstrip()) for _ in range(m): temp = sys.stdin.readline().rstrip() for i in range(n): if c[i][3 : 6] == temp: ans.add(i) print(len(ans))C. Path Graph?
self-loop와 multiple edge가 없는 그래프가 입력으로 주어질 때, 해당 그래프가 하나의 트리이면서 각 정점의 차수가 2이하 인지를 구하는 문제이다. 따라서 간단히 union-find로 모든 간선을 union하면서 현재 간선을 union했을 때 사이클이 생기는지 1차적으로 확인한다. 사이클이 생기지 않았다면 연결 요소가 1개인지를 확인하면서 동시에 각 정점의 차수가 1이상 2이하인지를 확인하여 정답을 출력하면 된다
import sys # find : 현재 정점이 속한 집합의 대표 정점을 리턴하는 함수 def find(x): if x == parent[x]: return x parent[x] = find(parent[x]) return parent[x] # union : 두 정점을 하나의 집합으로 연결하는 함수 def union(x, y): x, y = find(x), find(y) parent[y] = x # 입력부 n, m = map(int, sys.stdin.readline().split()) arr = [] # parent : 현재 정점이 속한 집합의 대표 정점을 저장하는 배열 parent = [i for i in range(n + 1)] # d : 각 정점의 차수를 저장하는 배열 d = [0] * (n + 1) for _ in range(m): a, b = map(int, sys.stdin.readline().split()) arr.append((a, b)) can = True for i in arr: # 현재 간선을 추가했을 때 사이클이 생기지 않는다면 if find(i[0]) != find(i[1]): # 현재 간선을 추가하면서 정점의 차수 추가 union(i[0], i[1]) d[i[0]] += 1 d[i[1]] += 1 # 현재 간선을 추가했을 때 사이클이 생긴다면 정답이 아님 else: can = False break if not can: print('No') else: temp = set() dcan = True # 각 정점이 속한 집합의 대표정점이 하나인지 확인하면서 각 정점의 차수가 2 초과거나 1미만인지 확인 for i in range(1, n + 1): temp.add(find(i)) if d[i] > 2 or d[i] < 1: dcan = False if len(temp) == 1 and dcan: print('Yes') else: print('No')D. Match or Not
길이가 다른 두 문자열이 주어지고, 문자열은 알파벳 소문자 혹은 물음표로 구성되어 있다. 물음표는 어떤 문자로도 바꿀 수 있다. 이 때 더 긴 길이의 문자열을 짧은 길의의 문자열로 자를 때 물음표를 특정 문자로 적절히 바꾸어서 두 문자열이 같은 지를 판단하는 문제이다. 글로는 이해가 힘들기 때문에 아래 그림을 통해 이해하면 쉽게 이해할 수 있다

<그림 1. 첫번째 경우> 위 그림 1은 첫번째 비교를 나타낸 그림이다. 더 긴 문자열을 S, 더 짧은 문자열은 T이다. 맨 첫번째 비교할 때는 S의 맨 끝 글자부터 비교가 이루어진다. 그림 상에서는 빨간색 글자인 "??c?"와 문자열 T를 비교하는 것이다. 물음표는 어떠한 문자로도 변경할 수 있기 때문에 "??c?"와 "?b?d"는 같아질 수 있다. 예를 들어, "??c?"는 "abcd"가 될 수 있고 "?b?d" 역시 "abcd"가 될 수 있다.

<그림 2. 두번째 경우> 위 그림 2는 두번째 비교를 나타낸 그림이다. 이번에는 그림 1과 비교하였을 때 문자열 S의 뒷부분 문자가 하나 줄어들고, 문자열 S의 앞부분 문자가 하나 늘어났다. 따라서 두번째 비교는 "a?c?"와 "?b?d"간의 비교가 되고 이번에도 물음표의 성질을 이용하면 두 문자열을 같게 만들 수 있다.

<그림 3. 세번째 비교> 위 그림 3는 세번째 비교를 나타낸 그림이다. 이번에는 그림 2와 비교하였을 때 문자열 S의 뒷부분 문자가 하나 줄어들고, 문자열 S의 앞부분 문자가 하나 늘어났다. 따라서 세번째 비교는 "a?c?"와 "?b?d"간의 비교가 되고 이번에도 물음표의 성질을 이용하면 두 문자열을 같게 만들 수 있다.

<그림 4. 네번째 비교> 위 그림 4는 네번째 비교를 나타낸 그림이다. 이번에는 그림 3와 비교하였을 때 문자열 S의 뒷부분 문자가 하나 줄어들고, 문자열 S의 앞부분 문자가 하나 늘어났다. 따라서 네번째 비교는 "a?f?"와 "?b?d"간의 비교가 되고 이번에도 물음표의 성질을 이용하면 두 문자열을 같게 만들 수 있다.

<그림 5. 마지막 비교> 위 그림 5는 마지막 비교를 나타낸 그림이다. 그림 1이 문자열 S의 뒷부분 문자로만 이루어져 있던 것처럼 그림 5에서는 문자열 S의 앞부분 문자로만 이루어져있는 것을 알 수 있다. 따라서 마지막 비교는 "a?f?"와 "?b?d"간의 비교가 되고 이번에도 물음표의 성질을 이용하면 두 문자열을 같게 만들 수 있다. 위 그림 1부터 5까지의 흐름을 통해 어떤 식으로 비교가 이루어지는 지 알 수 있다. 그러나 위와 같이 매 쿼리에 브루트 포스로 해결하려 하면 입력 크기 상 시간 초과를 피할 수 없다.

<그림 6. 각 비교 시 prefix와 suffix의 부분 매칭> 위 그림 6은 각 비교마다 원 문자열의 prefix인지 suffix인지 별로 나누어 부분 매칭의 결과를 나타낸 그림이다. 우선 첫번째 비교에서는 당연히 문자열 S의 앞부분에서 오는 문자가 없으므로 빈 문자열로 표기하였으며 문자열 S의 뒷부분에 오는 문자는 "??c?"이다. 이제 각각을 문자열 T와 비교해보면 prefix에서 만들어진 부분 문자열인 빈 문자열은 무조건 매칭이 가능하고, 마찬가지로 suffix에서 만들어진 부분 문자열인 "??c?"도 물음표의 성질을 이용하면 문자열 T와 매칭을 시킬 수 있다. 따라서, 최종적으로는 문자열 T와 매칭시킬 수 있다
하지만, 두번째 비교에서는 prefix에서 온 부분 문자열이 "q"가 되고 suffix에서 온 문자열이 "?c?"가 되므로 prefix 부분 문자열인 "q"와 문자열 T의 "k"와는 매칭이 되지 않는다. 그러나, suffix 부분 문자열인 "?c?"와 문자열 T의 "b??"와는 매칭이 된다. 따라서, 최종적으로는 매칭시킬 수 없다. 이렇게 각각의 비교에서 prefix와 suffix를 나누어 생각하고, 대응되는 문자열 T와의 비교를 또 나누어 생각해보면 $O(n)$만에 prefix와 suffix의 부분 매칭 결과를 알 수 있고, 최종 결과도 $O(n)$만에 구할 수 있으므로 시간안에 정답을 구할 수 있다.
import sys, math # 입력부 s = sys.stdin.readline().rstrip() t = sys.stdin.readline().rstrip() n, m = len(s), len(t) # pf : 각 비교의 prefix 부분 문자열과 문자열 t와의 부분 비교 결과값 pf = True # ans1 : 각 비교의 prefix 부분 문자열과 문자열 t와의 부분 비교 결과값을 저장하는 배열 ans1 = [True] # sf : 각 비교의 suffix 부분 문자열과 문자열 t와의 부분 비교 결과값 sf = True # ans2 : 각 비교의 suffix 부분 문자열과 문자열 t와의 부분 비교 결과값을 저장하는 배열 ans2 = [] # 문자열 s에서 각 비교시에 prefix 부분 문자열만 문자열 t와 부분 비교 for i in range(m): if s[i] != '?' and t[i] != '?' and s[i] != t[i]: pf = False ans1.append(pf) # 문자열 s에서 각 비교시에 suffix 부분 문자열만 문자열 t와 부분 비교 for i in range(m): if s[n - 1 - i] != '?' and t[m - 1 - i] != '?' and s[n - 1 - i] != t[m - 1 - i]: sf = False ans2.append(sf) # ans1과의 순서를 맞춰주기 위해 ans2를 뒤집고 마지막에 True값 추가 # 마지막에 넣는 True는 suffix가 빈 문자열인 경우를 추가하기 위해서이다 ans2.reverse() ans2.append(True) # 두 부분 비교가 모두 True인지 그렇지 않은지에 따라 정답 출력 for i in range(m + 1): if ans1[i] & ans2[i]: print('Yes') else: print('No')E. Karuta
n개의 문자열이 주어지고, 각각의 문자열에 대해서 자기자신을 제외한 다른 문자열 중 공통으로 일치하는 prefix의 길이 중 최대값을 출력하는 문제이다.

<그림 1. 임의의 예시> 위 그림 1에서 "asdqd"와 가장 길게 매칭되는 prefix의 길이는 2이고, 그 때 매칭되는 문자열은 "asx"이다. "xcvf"와 가장 길게 매칭되는 prefix의 길이는 4이고, 그 때 매칭되는 문자열은 "xcvfwef"이다. 따라서 이런 논리대로 정답을 구하면 2, 4, 1, 2, 4가 된다. 가장 길게 매칭되는 prefix의 성질을 이용하면 이분 탐색을 이용하면 시간안에 정답을 구할 수 있을 수도 생각할 수 있다. 그러나, n의 길이가 50만이고, 전체 문자열의 길이의 합 역시 50만이기 때문에 이분 탐색을 쓴다고 해도 시간 초과를 피할 수 없다
개인적으로 이 문제는 정렬과 트라이를 사용하면 쉽게 풀 수 있다고 생각한다. 트라이는 풀이에 있어 보조적 수단일 뿐, 핵심은 그리디한 성질을 이용하여 정렬하는 것이라 생각한다. 우선 길이 순으로 오름차순 정렬을 하는 경우부터 생각해보자
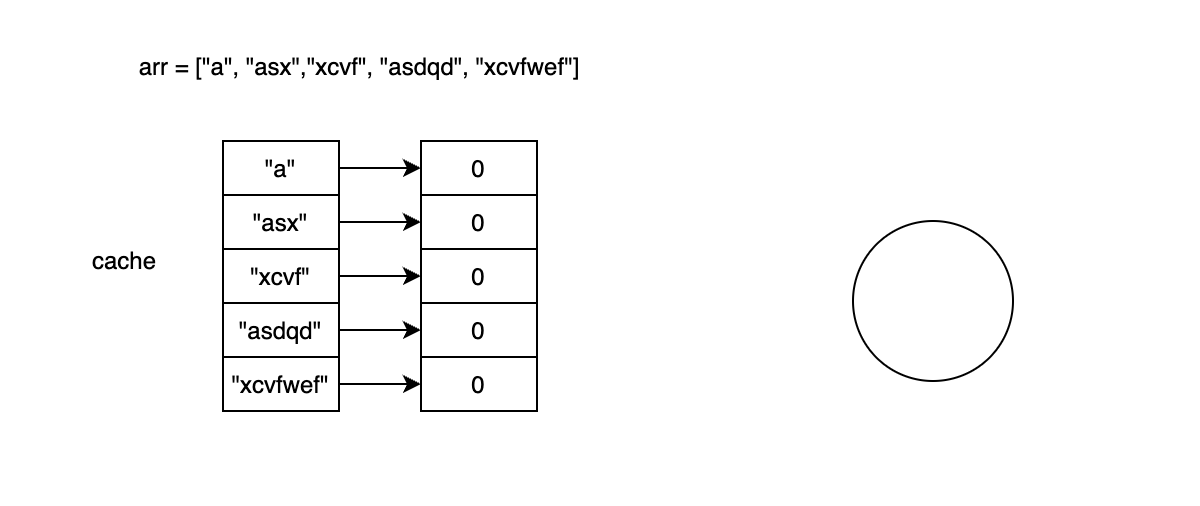
<그림 1. 첫 글자를 트라이에 삽입하는 경우> 위 그림 1에서는 정렬된 arr에서 첫번째 글자인 "a"를 트라이에 삽입하는 경우를 나타낸 그림이다. 당연히 아직 트라이에 아무것도 삽입된 게 없으므로 현재 글자인 now와 매칭되는 최대 prefix길이는 0이 된다. cache는 arr에 있는 문자열을 key, 최대 prefix 길이를 value로 갖는 dictionary이다

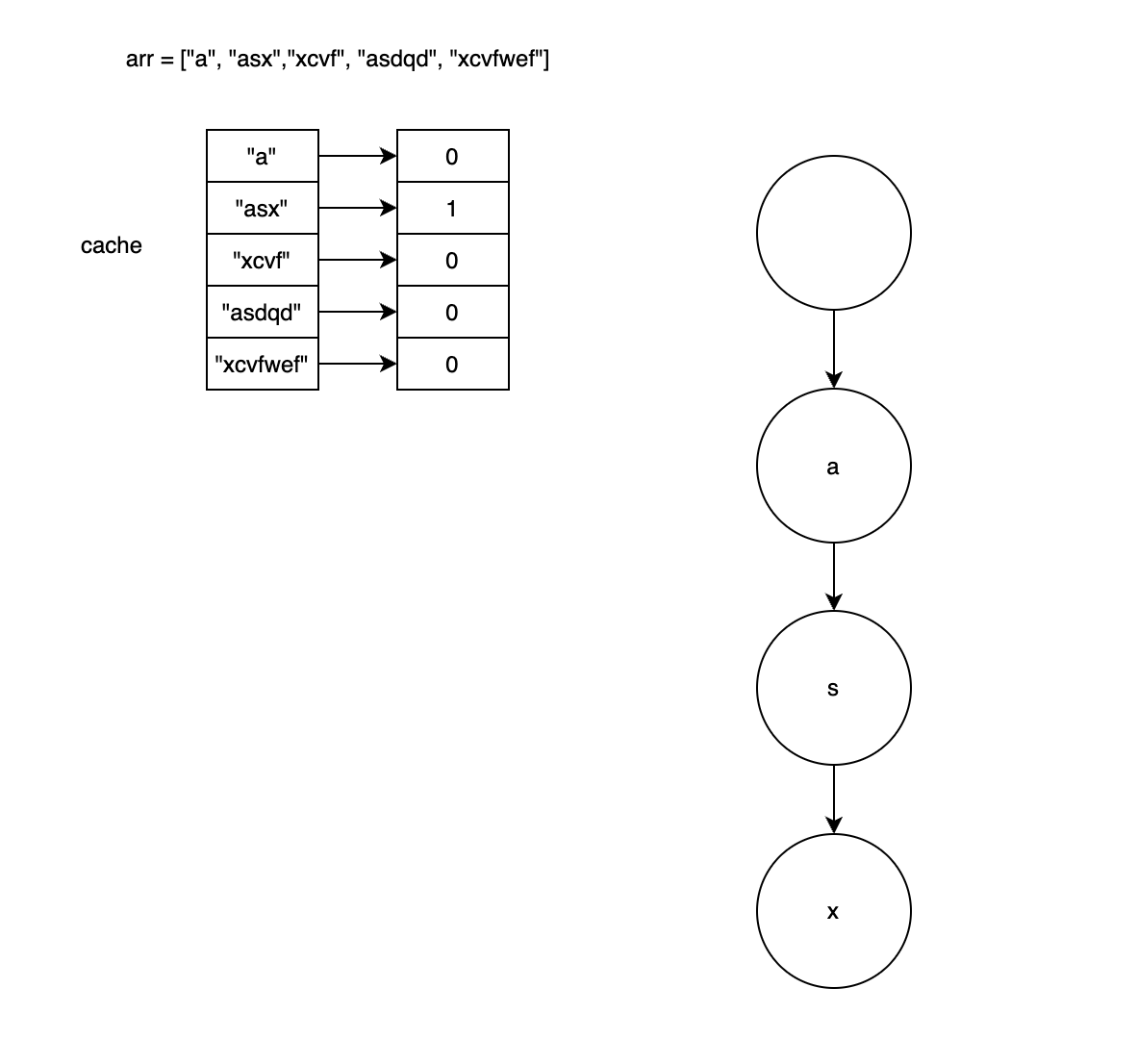
<그림 2. 두번째 글자를 트라이에 삽입하는 경우> 위 그림 2에서는 정렬된 arr에서 두번째 글자인 "asx"를 트라이에 삽입하는 경우를 나타낸 그림이다. 첫번째 글자인 "a"가 트라이에 삽입되어 있으므로 만일 "asx"를 삽입하게 되면 첫 글자인 "a"는 같기 때문에 이 때 매칭되는 prefix의 최대 길이는 1이 된다.
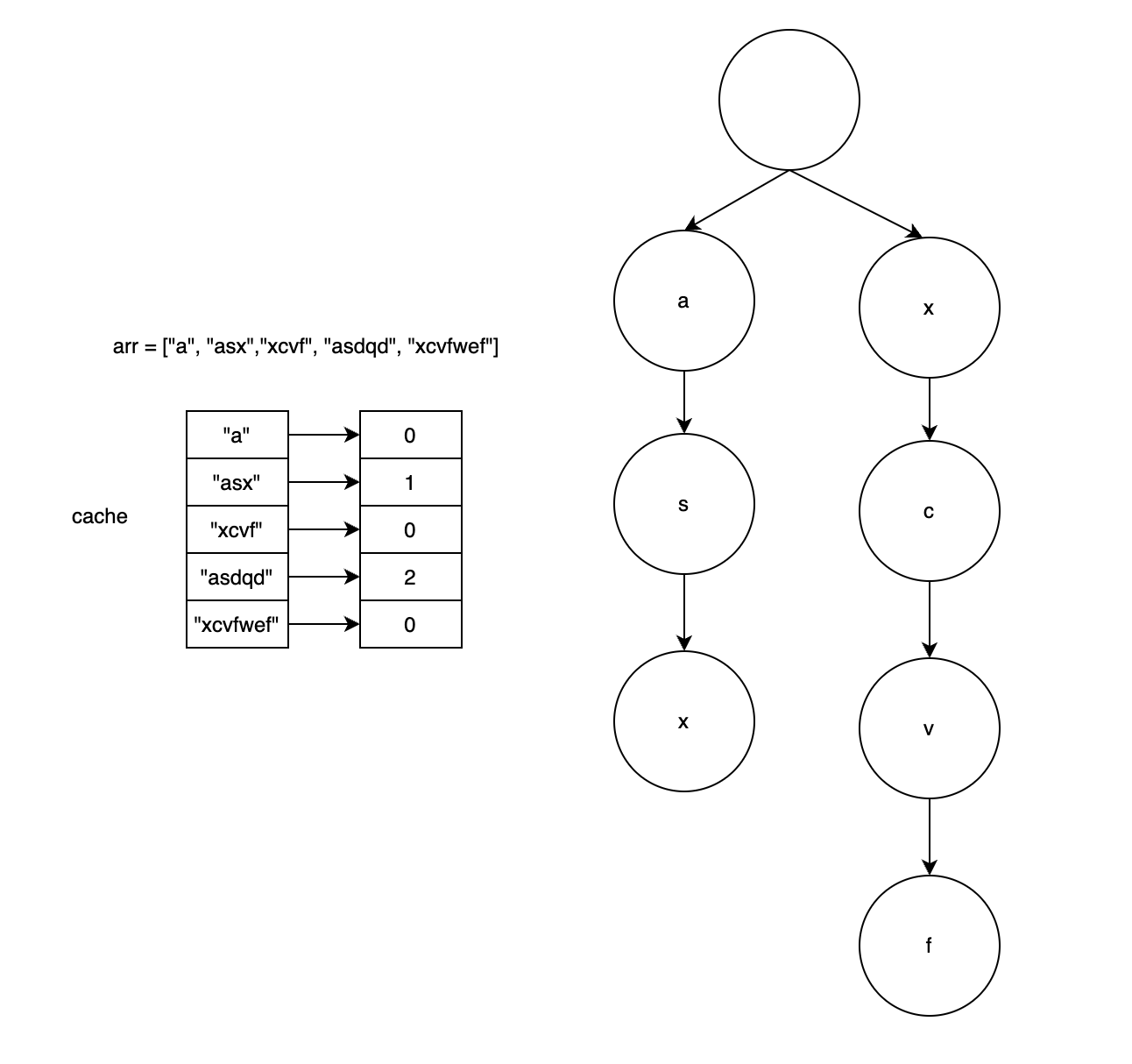
<그림 3. 세번째 글자를 트라이에 삽입하는 경우> 위 그림 3에서는 정렬된 arr에서 세번째 글자인 "xcvf"를 트라이에 삽입하는 경우를 나타낸 그림이다. 이 때는 트라이의 루트에서 탐색을 하게 되면 a밖에 없기 때문에 최대 매칭 prefix의 길이는 0이 된다
<그림 4. 네번째 글자를 트라이에 삽입하는 경우> 위 그림 4에서는 정렬된 arr에서 네번째 글자인 "asdqd"를 트라이에 삽입하는 경우를 나타낸 그림이다. 이미 "asx"가 트라이에 있기 때문에 "as"까지는 매칭이 되므로 최대 매칭 prefix의 길이는 2가 된다
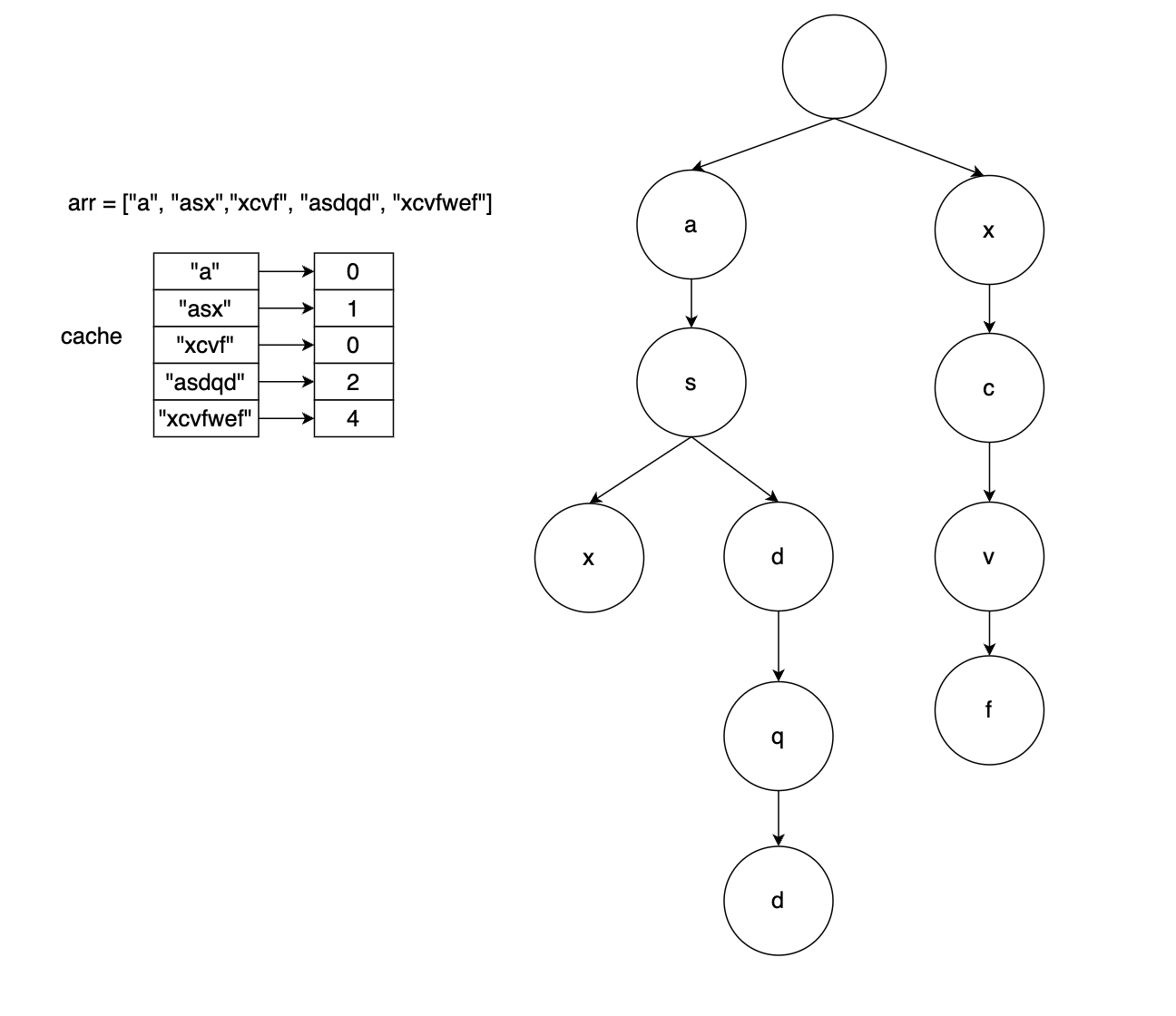
<그림 5. 다섯번째 글자를 트라이에 삽입하는 경우> 위 그림 5에서는 정렬된 arr에서 다섯번째 글자인 "xcvfwef"를 트라이에 삽입하는 경우를 나타낸 그림이다. 이미 "xcvf"가 트라이에 있기 때문에 "xcvf"까지는 매칭이 되므로 최대 매칭 prefix의 길이는 4가 된다. 마지막 글자까지 트라이에 삽입을 했을 때 cache의 결과를 보면 일부 문자열은 정답과 같은 숫자이지만, 일부 문자열은 정답과는 다른 숫자를 가진다. 예를 들어 "a"는 실제로는 1이지만 cache 상에서는 0이다. 왜냐하면 길이가 긴 문자열일 수록 확률적으로 자신보다 짧은 문자열에서 최대 prefix의 길이를 찾을 수 있는 확률이 더 높기 때문이다. 극단적으로 가장 긴 길이의 문자열을 삽입하는 경우에는 당연히 그 때 매칭되는 prefix의 최대 길이가 맞는 것이다.
하지만 길이가 짧은 문자열일 수록 이와 반대로 확률적으로 자신보다 긴 문자열에서 최대 prefix의 길이를 찾을 수 있는 확률이 더 높기 때문에 정답 값보다 더 작은 값을 가지게 된다. 따라서 이런 왜곡을 바로 잡기 위해서는 길이 순으로 내림차순으로 정렬하여 자신보다 짧은 문자열만 트라이에 존재하는 경우 외에도, 자신보다 긴 문자열만 트라이에 존재하는 경우까지 탐색해야 한다
그런데 이 논리에는 하나의 함정이 있는데 바로 같은 길이의 문자열인 경우이다. 만약 모든 문자열들이 다 같은 길이라면 2차적으로 비교할 기준을 만들어줘야 한다. 따라서, 정렬을 할 때 1차적으로는 길이로 정렬하고 2차적으로는 사전상 순서로 정렬을 해줘야 같은 길이로만 이루어진 경우에도 정확하게 정답을 구할 수 있다
import sys, math # 트라이 클래스 class Trie: def __init__(self): self.trie = {} # self.temp는 그림 상 cache와 같은 역할을 담당 self.temp = {} # go : 현재 word를 저장할 때 최대 prefix 갯수를 temp에 저장하는 함수 def go(self, word): cnt = 0 t = self.trie for c in word: if c not in t: t[c] = {} else: cnt += 1 t = t[c] self.temp[word] = cnt # 입력부 n = int(sys.stdin.readline()) arr = [] at = Trie() dt = Trie() ans = dict() for _ in range(n): arr.append(sys.stdin.readline().rstrip()) # asc : 1차적으로 길이 순, 2차적으로 사전 순으로 오름차순 정렬한 리스트 asc = sorted(arr, key=lambda x : (len(x), x)) # des : 1차적으로 길이 순, 2차적으로 사전 순으로 내림차순 정렬한 리스트 des = sorted(arr, key=lambda x : (len(x), x), reverse=True) # 각 문자열을 트라이에 저장 for i in asc: at.go(i) for i in des: dt.go(i) # 오름차순 삽입 결과 내림차순 결과 중 최대값으로 저장 for i in arr: ans[i] = max(at.temp[i], dt.temp[i]) # 정답 출력 for i in arr: print(ans[i])후기 : C번까지는 무난하게 풀었으나 D번을 조금 늦게 풀었다. E번에 진입했을 때 딱 1시간 남았을 때였는데 트라이까지는 생각이 미쳤으나 그리디한 성질을 파악하는데 아이디어가 떠오르지 않아 뇌절을 씨게 해버려 대회 중에는 풀지 못했으나, 업솔빙으로 해결하였다. C번의 경우 대회 테스트 케이스가 약간 부실하여 틀린 풀이로도 통과되는 이슈가 있었다.
사실 나도 틀린 풀이였지만 느슨한 TC 덕분에 통과해서 꿀빰. 매번 천등 후반대의 퍼포먼스를 보이는데 이렇게 하다보면 그린 중위에서 막힐게 자명하다... 제발 잘 좀하자'AtCoder' 카테고리의 다른 글
Atcoder Beginner Contest 285 후기 (4) 2023.01.17 Atcoder Beginner Contest 272 후기 (0) 2022.12.07 Atcoder Beginner Contest 271 후기 (4) 2022.12.06 Atcoder Beginner Contest 270 후기 (4) 2022.11.22 Atcoder Beginner Contest 269 후기 (0) 2022.11.17